오랜만에 논문을 블로그에 포스팅한다.
Meta-reinforcement learning 에 대한 흐름을 보려고 찾아본 논문이다.
Keywords: #meta-learning, #multi-task reinforcement learning, #benchmarks
https://arxiv.org/pdf/1910.10897.pdf
Abstract :
이 논문에서는 open-source simulated benchmark를 제시한다. 완전히 새롭게 행해진 태스크를 통해 가속화하여 개발할 수 있는 알고리즘을 개발하는 것이 목표. Meta reinforcemnt learning과 muli-task learning의 7개의 sota(state of the art) 모델을 사용해서 평가했는데 성공적으로 학습했다.
1 Introduction :
현재 강화학습에서 핑퐁이나 손으로 조작하는 문제 등에서 sota 모델들은 한번의 narrowly-defined skill을 통해서 사람보다 더 많은 정보를 얻을 수 있다. 특정 영역에서는 조작이나 locomotion은 각각의 태스크들이 비슷한 구조를 공유한다. (예를들어 많은 조작 태스크들은 잡기와 물체 움직이기를 포함하고 있음.) 현재로는 이런 비슷한 구조의 태스크들을 학습해야 빠르게 학습할 수 있다.
최근 멀티 태스크 강화학습에서는 multiple task를 해결한 하나의 policy를 학습하는 것을 목표하고있고, 반면 메타 러닝은 다수의 태스크를 학습하여 새로운 태스크에 빠른 적응을 할 수 있도록한다. 이런 메소드들은 설계된 benchmark의 부제와 평가 수단이 없어서 한계를 겪고있다. mutli task RL에서는 atari suite의 여러 게임들을 효율적으로 해결하는 것을 사용하고 있으며, meta RL은 다리 로봇을 각자 다른 방향으로 움직이게하는 것을 학습하고 새로운 방향으로는 얼마나 잘 움직이는 것을 평가한다.
While these are technically distinct tasks, they are a far cry from the promise of a meta-learned model that can adapt to any new task within some domain.
multi task와 meta 학습 방법의 기능을 연구하고 의미있게 구별되는 작업에 대해 신속하게 적응하는 새로운 알고리즘을 설계할 수 있도록 하려면 구조 공유가능하고 일반화가 가능한 작업 공간이 필요하다. 본 연구는 50개의 다양한 조작 태스크를 포함하며 각자 개별 태스크에 대해서 이전의 메소드들이 어떻게 수행했는지 평가가 핵심이다. 같은 환경과 구조를 공유하는 독자적인 태스크들의 대형 세트를 제공하는 것이 multi task 연구에 도움이 될 것이다.
By doing so, we can enable meaningful generalization across many tasks and achieve the full potential of meta-learning as a means of incorporating past experience to make it possible for robots to acquire new skills as quickly as people can.
2 Related Work :
multi task RL에서는 Arcade learning Environment를 많이 사용한다. 아타리 게임은 비주얼적인 부분이나, 조작 및 목표에서도 상당한 차이가 있어서 공유 학습을 통해 효율성을 얻기가 어려웠기 때문에 대조적으로 이 논문에서는 다양한 작업을 동일한 로봇이 동일한 행동 공간을 사용하는 환경을 제안한다.

3 The Multi-Task and Meta-RL Problem Statements :
이 논문에서는 benchmark를 이용하여 meta RL과 multi task RL의 일반화를 목적으로 한다. 따라서 해당 이 섹션에서는 multi task RL과 Meta RL 의 문제 상태를 정의하고 몇몇의 challenge를 설명한다.
Notation :

Multi-task RL problem statement :
multi-task RL의 목표는 하나의 z(task ID)로 인코딩된 하나의 태스크를 학습하는 것이 목표이다. 이 폴리시는 보상의 기댓값을 최대화하는 것이 목표이며 각 태스크는 p(T) 확률에 따라 분포되어있다. 태스크의 개별적인 테스트 셋은 없으며 멀티 태스크 RL은 training task의 평균 성적을 통해서 평가된다. (따로 테스트용 태스크는 없다는 얘기)
Meta-RL problem statement :
Meta RL의 목표는 로운 테스트용 태스크에 빠르게 적응하기 위한 폴리시를 학습할 training task들을 단계화하는 것이 목적이다. 테스트 셋과 트레이닝 셋 모두p(T)에 의해 분포한다. Meta-training set으로 여겨지는 training set은 test set과과 구별한다. 메타 트레이닝동안 학습 알고리즘은 M개의 태스크를 사용한다. 테스트동안은 새로운 태스크를 사용하고 빠르게 적응하여 적은 수의 샘플 데이터를 이용하여 높은 보상을 받는 것을 목표를 한다.
4 Meta-World :
The Space of Manipulation Tasks: Parametric and Non-Parametric Variability :
Meta-World의 태스크 T는 tuple (reward function, initial object position, target position)로 정의된다. Meta-learning은 두가지 중요한 전제가 있다.
첫째, 메타 트레이닝과 메타 테스트 태스크들은 같은 확률함수 p(T)를 통해 도출된다.
두번째, 각 태스크의 분포함수 p(T)는 공유하는 구조를 보여줌으로써 효율적으로 새로운 태스크에 적응가능하도록 한다.
만약 분포함수가 특정 태스크에 집중하도록 되어 있다면 완전히 새로운 태스크의 일반화에는 맞지 않다. 따라서 meta world는 다양한 50가지 태스크를 통해 연속적인 parameter variation을 두어 각 태스크의 차이를 구별하지 못하게 한다.
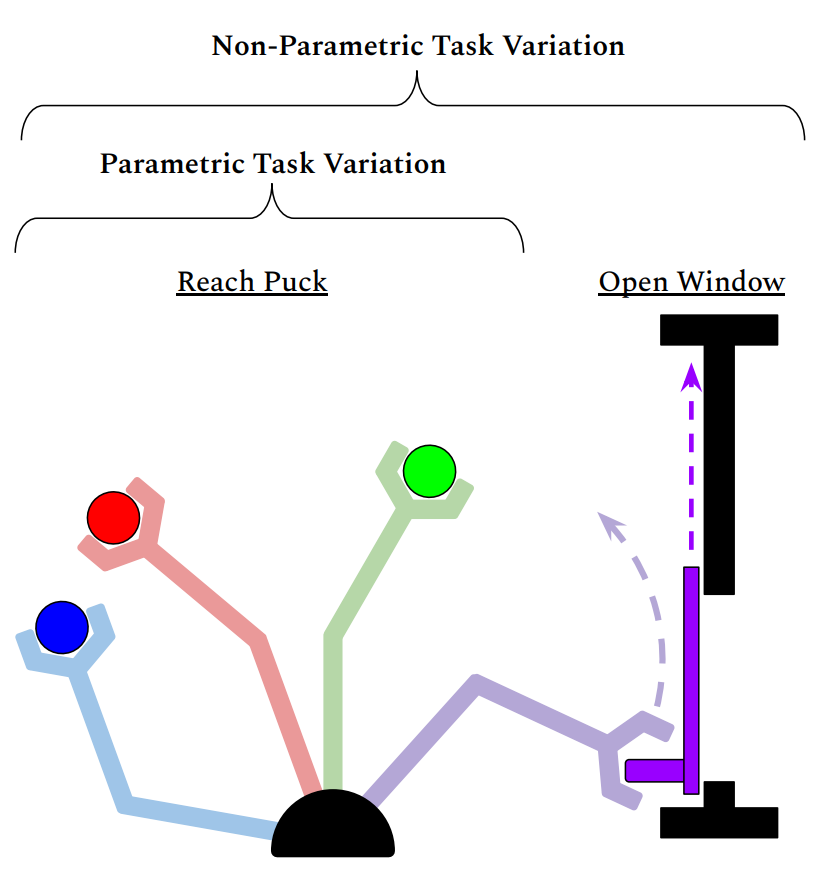
이런 non-parametric variation은 공유 구조를 충분히 보여주지 못하거나, 각 태스크들을 기억하는 것을 피하기 위해서 필요한 task사이의 overlap이 결여되는 위험을 가진다. 따라서 이런 어려움을 참고하여 figure 2처럼 각 태스크들은 parametric variation을 두어 목적과 목표 상태의 차이를 둔다. 이 매개 변수 가변성을 도입하면 훨씬 더 넓은 다양한 작업뿐만 아니라 메타 학습 모델이 위치를 변경하면 가능한 조작 작업의 공간이 더 넓어지기 때문에 완전히 새로운 작업을 더 빨리 획득하도록 일반화된다. 변수의 변화가 없는 모델은 예를 들어 특정 위치에있는 모든 물체가 문인 반면 모든 물체는 다른 위치에는 서랍이 있다고 생각한다. 따라서 작업 내에서 충분한 작업과 변형이 있으면 질적으로 구별되는 작업 쌍이 겹칠 가능성이 높아 일반화의 촉매제 역할을 한다.
Actions, Observations, and Rewards :

작업이 현재의 단일 작업 강화 학습 알고리즘 (다중 작업 및 메타 RL 알고리즘을 평가하기위한 전제 조건)의 범위 내에 있도록 보장하기 위해 각 작업을 수행하는 각 작업에 대해 잘 형성된 보상 함수를 설계함.
Evaluation Protocol :

- Meta-Learning 1 (ML1): Few-shot adaptation to goal variation within one task.
- Multi-Task 1 (MT1): Learning one multi-task policy that generalizes to 50 tasks belonging to the same environment.
- Multi-Task 10, Multi-Task 50 (MT10, MT50): Learning one multi-task policy that generalizes to 50 tasks belonging to 10 and 50 training environments, for a total of 500, and 2,500 training tasks.
- Meta-Learning 10, Meta-Learning 45 (ML10, ML45): Few-shot adaptation to new test tasks with 10 and 50 meta-training tasks.
실험 결과로는 논문 참고!
기존 알고리즘들이 환경 태스크가 다양할수록 어려워하고 있지만, 앞으로의 연구에 도움이 될 것이라고 말하며 논문이 끝남!



