Accelerating Reinforcement Learning with Learned Skill Priors
Publications accepted to CoRL 2020.
corlconf.github.io
#Reinforcement Learning, #Skill Learning, #Transfer Learning
**공부용으로 적는 것이니 정확하지 않음**
: Abstract
문제점 : 지금 강화학습은 새로운 task를 학습하기 위해서는 prior experience에 강하게 의존함. + 모든 task들을 기본적인 것부터 학습하려 함.
그래서 모든 걸 다 똑같은 확률로 학습할 필요가 없으니까 전체 skill prior(사전 스킬 지식! 땡큐!)을 학습하는 것을 제안함.
이 논문의 모델은 SPiRL(Skill-Prior RL)이라고 명명하고 manipulation이랑 navigation으로 얼마나 효율적인지 테스트함.
: 1. Introduction
Intelligent agent들은 스킬들을 이전 경험에 의거해서 효율적으로 배울 수 있다. 하지만 강화학습에서의 agent는 모든 스킬들은 밑바닥부터 배운다는 점이 한계다(학습 효율 완전 안 좋음). 이렇기 때문에 학습을 자연스럽게 많이 해야 하는데 모인 데이터들은 리워드나 명확한 태스크가 아닌 이상 학습에 사용하기도 좋지 않음.
->scalable 하게 이런 구조화되지 않은 학습 경험들을 조정해서 빠르게 학습 가능하게 하는 것이 목표!
-스킬을 뽑아내야 함으로써 유틸라이즈 시켜야 하는데 (스킬 = 유용한 행동 나타내지는 액션) 이걸 다시 downstream task에 다시 쓸 수 있는 녀석으로 뽑아내야 한다. 스킬들은 태스크나 리워드 정보 없이 학습될 수 있으며 새로운 태스크나 환경에도 이전될 수 있어야 한다.
후속 태스크를 해결하기 위해서 배운 스킬 들을 사용하려면 이런 접근들로 뽑힌 스킬들의 셋을 action space로한 high-level policy를 학습해야 한다.
이 아이디어의 핵심은 skill prior를 이용해서 스킬 라이브러리에서 exploration을 스킬 스페이스에서 효율적으로 하는 것이다. 직관적으로 데이터셋 안의 모든 skill들이 똑같이 필요하진 않다는 것을 알 수 있다.

이것 아이디어를 어떻게 maximum-entrophy RL 알고리즘에 적용할 것인지는 후에 설명.
: 2. Related work
패쓰!
: 3. Approach
앞서 말한 아이디어의 문제점을 두 가지로 쪼개서 접근할 것이다.
1. The extraction of skill embedding and skill prior from offline data
2. The prior-guided learning of downstream tasks with a hierarchical policy
- 3.1 Problem Formulation
dataset D (state-action 트래젝토리로 구성된 agent 데이터)
이전에 학습된 에이전트 들을 이용해서 다양한 태스크 셋에서 모음, 에이전트들은 자동적으로 그들의 환경에서 탐색한다 + 사람과의 teleoperation이 추가로 가능
**유의할 점**
- 데이터들이 구조화되지 않아야 하므로 태스크, sub-skill에 대한 annotation 및 reward 정보는 포함되지 않는다.- 모방 학습과는 대조적으로 후속 태스크에 대한 설루션을 포함하지 않는다.

- 3.2 Learning Continuous Skill Embedding and Skill Prior

먼저 태스크를 하는데 필요한 skill posterior(regurization)를 파악하고, 그 태스크에 사용할 수 있는 skill prior을 학습(prior training)한다. 이게 전체적으로 효율적인 학습을 하게 해 준다는 것. 스킬 디코더를 통해서 이 녀석들을 agent가 움직일 수 있는 action으로 출력함(reconstruction).
스킬 임베딩 스페이스(Z)를 학습하기 위해서 stochascit alatent variable model을 학습함. (fig2) 오프라인 데이터셋에서 무작위로 H-step 궤적을 샘플링한다. 그리고 evidence lower bound(ELBO)에 의거해서 맥시마이즈 함.

베타는 regularization term을 튜닝하기 위한 매개변수임. 다양한 스킬 임베딩 스페이스를 학습하기 위해서는 skill encoder와 decoder를 뉴럴 네트워크로 구현함. Prior p(z)는 가우시안 분포로 셋팅함. 한번 훈련을 하고 나면 스킬을 샘플링해서 디코더에 보내버림.
스킬을 임베딩 하기 위해서는 skill prior를 학습해야 하고 skill prior를 아래처럼 정리함.
skill prior (p_a(z|.)) :
- 환경과 태스크에 간단하게 적용 가능해야지만 현 상황에서 탐색에 유용한 정보를 포함해야 함
- 마지막에 실행된 스킬들(z_t-1)과 현재 상태(s_t)에 대해서 가능한 선택지를 나타냄
- 논문에서는 상태의 조건부 확률로 skill prior를 학습함
이 skill prior을 학습하기 위해서 예상되는 prior과 추론된 skill posterior사이의 KL Divergence를 미니마이즈했음.
- 3.3 Skill Prior Regularized Reinforce Learning
skill embedding을 후속 task 학습에 사용하기 위해서 hierarchical policy learning scheme를 사용함. 정확히는 policy를 action에 대해 학습하기보다 state에 대한 스킬 policy를 학습하고 이것의 아웃풋이 스킬 임베딩 임. 그 후에 스킬 임베딩은 action sequence로 디코드 된다. 다음 스킬을 샘플링하기 전에 H step 만큼 action들을 수행함. 이런 계층적 구초를 통해서 long-horizon task learning을 효율적으로 진행할 수 있게 함.


기술이 많을 수록 많은 동작을 포함할 수 있도록 하기 때문에 정책 학습에 어려움을 겪는다. action의 범위가 큰 데이터셋은 내장된 skill의 수가 늘어난다. 따라서 탐색에 어려움을 가지게 되고 skill prior을 사용함으로써 효율적인 탐색을 이뤄지게 한다. Skill prior이 최대 엔트로피 RL 알고리즘에 자연스럽게 통합되는 방법이 나옴!

추가된 엔트로피 용어는 policy와 이전의 균일한 action 사이의 negated KL divergence임.
이 부분은 잘 모르겠음ㅜ

: 4. Experiments
저자들이 원한 실험의 목표
(1) Can we leverage unstructured datasets to accelerate downstream task learning by transferring skills?
(2) Can learned skill priors improve exploration during downstream task learning?
(3) Are learned skill priors necessary to scale skill transfer to large datasets?
- 4.1 Evrionments & Comparions

실험 영상은 위의 링크에서 찾아볼 수 있습니당
실험 세부사항은 패쓰!
Baseline에 사용된 알고리즘들 :


- 4.2 Maze Navigation
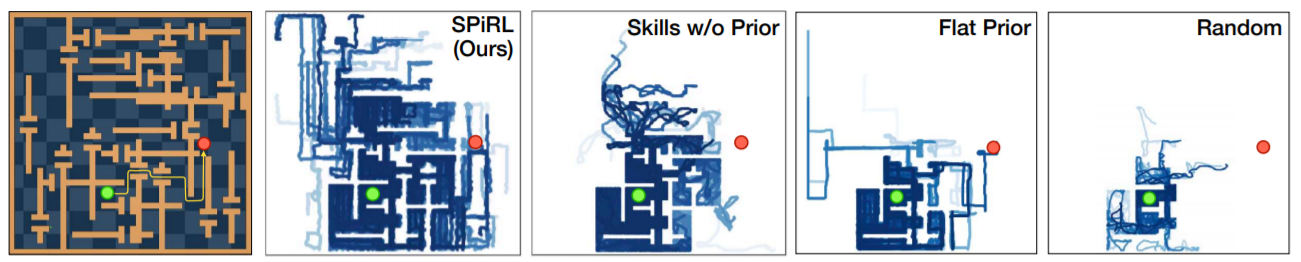
fig 4. 에서 볼 수 있듯이 각 maze navigation은 다른 baseline들은 성공하지 못한 것을 SPiRL 혼자 성공했는데, 이 같은 결과는 탐색에 있어서 가지는 차이 때문! Random으로 exploration을 시켰을 때 collision이 일어나기 때문에 성능이 좋지 못했음.
- 4.3 Robotic Manipulation
로봇을 이용하여 블록 쌓기와 부엌 실험을 둘 다 진행했다. 두 환경 모두에서 학습된 skill embedding과 추출된 skill prior을 함께 사용하는 것이 과제를 해결하는 데 필수적이었음. non-hierarchical action prior ("Flat Prior")을 사용하는 것은 데이터를 클로닝 하는 것과 비슷해 보였으나 긴 시간을 수행해야 하는 task를 성공시키지 못했다. skill prior을 사용하지 않고 학습을 했을 때에는 아주 드물게 블록을 쌓거나 부엌 환경에서 물체를 조작하게 했다. 너무 넓은 범위의 skill space이기 때문에 효율적으로 학습되지 않았기 때문이다.
: 5. Conclusion♥

conclusion은 항상 아름다우니까 영어로 ㅎㅎ
실험에 대한 디테일이나 모르는 개념 정리가 많이 필요할 것 같다.
appendix를 읽는 습관도 들여야지!
끝!!
'공부쓰 > Paper reviewth' 카테고리의 다른 글
| [CoRL 2020] Learning Latent Representations to Influence Multi-Agent Interaction (2) | 2021.02.05 |
|---|---|
| 대망(大亡)의 SAC(Soft Actor-Critic) 논문 정리 (7) | 2021.02.02 |
| 논문 읽는 나만의 꿀팁s... (6) | 2020.12.20 |



