Soft Actor-Critic은 정말 연이 깊은 알고리즘이다.
잇님들의 꾸준한 요청이 있었던 (자신감이 떨어져 올리고 싶지 않았던) sac 논문 정리를 올려본다.
수식이 많은 논문은 내용이 어떻든 읽는데 속도가 너무 오래 걸리는 것 같다!
하지만 열심히 썼으니 누군가에게는 도움이 되기를 >_<
⭐ㅇㄱㅎ 읽지마 🌚
+ Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor

0. Abstract
Model-free deep reinforcement learning 다양한 분야의 태스크에 사용되고 있다. 하지만 이런 메소드를 사용하면 고전적으로 두가지 문제에 시달린다.
- 높은 샘플 복잡도
- 하이퍼 파라미터 수정 의존성이 높은 것
이 두개의 문제는 복잡한, 리얼월드 태스크에 적용하기에 한계를 만든다. 이 논문에서는 엔트로피를 최대화한 off policy actor critic deep RL, soft actor-critic을 제안한다. actor는 엔트로피를 최대화하면서 받을 수 있는 보상도 최대화하는 것을 목적으로 한다. 즉 랜덤하게 행동하면서 성공을 하는 것을 목적으로 한다.
1. Introduction
RL과 Neural network와 같은 고용량 함수 근사값의 조합은 광범위한 자동화를 가능하게 한다. 하지만 이 모델들을 리월월드에 적용하는 것에는 두가지 문제가 있다.
- 비효율적인 샘플링
- 하이퍼 파라미터 수정에 의존성이 높음
RL이 샘플링에 비효율적인 이유는 on-policy learning이기 때문이다. TRPO, PPO나 A3C 같은 deep RL은 각 step마다 새로운 샘플들을 필요로 한다. 필요한 단계 당 그라디언트 step 및 샘플 수가 작업 복잡성과 함께 증가함에 따라 비용도 크게 증가한다. Off-policy 알고리즘은 과거의 경험을 재사용하는 것을 목표로 한다. Q 러닝 기반의 알고리즘에는 적용이 비교적 간단하지만, off-policy 알고리즘을 고차원, 비선형적 근사에 접목시키는 것은 어렵다.
연속적인 상태와 액션 공간을 위한 효율적이고 안정적인 free deep RL algorithm 모델을 디자인하는지 연구했다. 이를 위해 최대 엔트로피 프레임 워크를 사용하여 엔트로피 최대화 기간으로 표준 최대 보상 강화 학습 목표를 확장한다. 맥시멈 엔트로피는 탐색과 로버스트함을 구현한다. 그러나 계속해서 샘플링의 비효율적이 부분에서는 문제가 발생한다.
이 곰국에서는 안정성과 샘플 효율성을 보완한 soft actor-critic (SAC) 모델을 제안한다. 이 알고리즘은 복잡해보이는 고차원 태스크들까지 확장한다.
2. Related Work
패스 차후에 추가...
3. Preliminaries
3.1 Notation

3.2 Maximum Entropy Reinforcement Learning
고전적인 RL은 리워드를 합을 최대화하는 것이다.
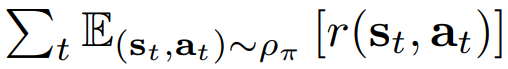
Maximum Entropy RL Policy의 entropy 기댓값 :
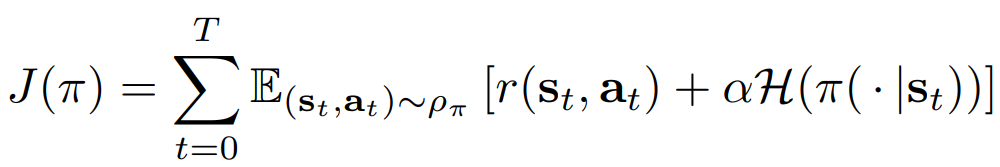
매개 변수 α는 보상에 대한 엔트로피 항의 상대적 중요도를 결정하므로 최적 정책의 확률성을 제어한다. 최대 엔트로피 objective는 기존 강화 학습에서 사용되는 표준 최대 예상 보상 objective와 다르지만 α → 0으로 보내서 기존의 objective로 돌릴 수 있다.
이 objective는 많은 개념적 실용적 이점을 가진다. 첫째로는 이 정책은 더 광범위하게 탐색하도록 장려하는 동시에 가능성이 없는 길은 가지 않는다. 두번째로 여러 optimal을 관측할 수 있다.
4. From Soft Policy Iteration to Soft Actor-Critic
off policy sac는 policy iteration의 maximum entropy 변형에서 파생된다. 먼저 알고리즘이 최적의 정책에 수렴하는지 확인한 다음 실용적인 deep RL 알고리즘을 제시함.
4.1. Derivation of Soft Policy Iteration
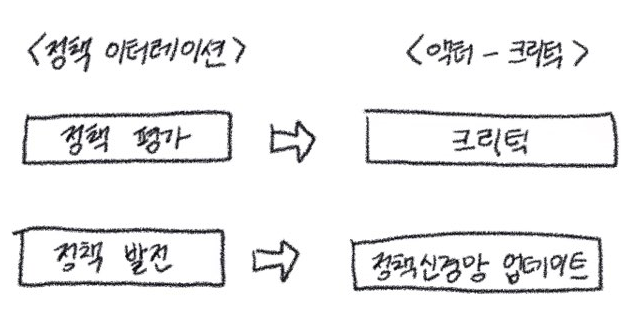
Policy iteration 구조에서 정책 평가와 정책 발전 단계로 나눌 수 있는데 우선 정책 평가에서 일어나는 일은 아래와 같다.
--
soft한 policy iteration의 평가 스텝마다 우리는 폴리시의 파이의 밸류를 Equation 1 을 사용하여 계산한다. Q 값은 반복하여 계산 한다.
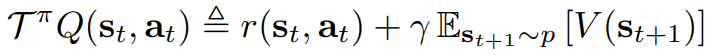
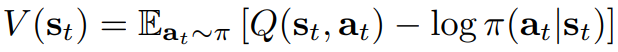

정책 발전
---
정책 발전 단계에서는 새로운 exponential한 Q 평션을 이용해서 폴리시를 업데이트한다. 이런 업데이트 방식은 정책의 소프트 벨류를 이용하여 더 나은 정책으로 업데이트 되는 것이 보장된다.
정책 발전 단계에서 각 상태마다 정책을 다음과 같이 업데이트 한다.
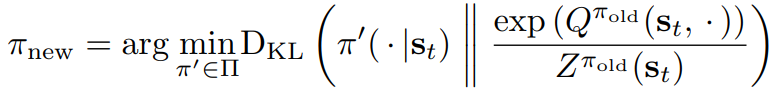
Z는 분포를 정규화하고 새 정책에 대한 그라디언트에 기여하지 않으므로 무시할 수 있다. 식 1의 목표와 관련하여 새로운 정책이 기존 정책보다 더 높은 가치를 가지고 있음을 보여준다. 이 결과를 Lemma 2에서 아래처럼 공식화한다.

전체 소프트 정책 반복 알고리즘은 소프트 정책 평가와 소프트 정책 발전 단계를 번갈아 가며 정책 중 최적의 최대 엔트로피 정책으로 수렴한다. Continuous domain에 적용하기 위해서 근사화 시켜야하지만 너무 계산량이 많다. 따라서 실용적인 새로운 알고리즘 soft actor-critic을 제시한다.

4.2. Soft Actor-Critic
대규모의 continous domain에서는 soft policy iteration에 대한 실용적인 근사를 유도해야한다. Q 함수와 정책 모두에 대해서 함수 근사치를 사용하고 정책 평가(Soft Q function) 및 발전을 하는 대신에 뉴럴 네트워크로 근사하고 경사하강법을 이용하여 최적화한다.

The soft value function은 the squared residual error 최소화하는 것이 Objective function이다. D는 리플레이 버퍼에 저장된 샘플링된 state와 action 쌍 distribution이다.
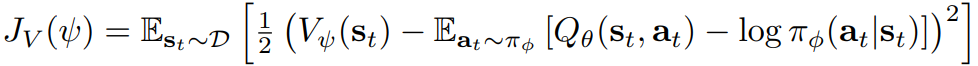
soft Q 펑션 파라미터는 Bellman residual을 최소화하도록 학습한다.
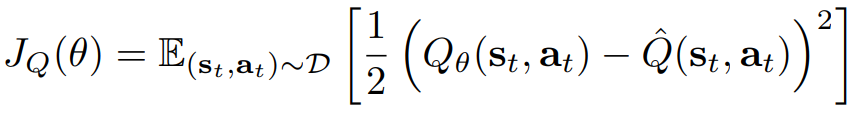
최적화 하기 위해서 SGD를 사용하기 위해서 gradient를 사용하면 아래와 같다.
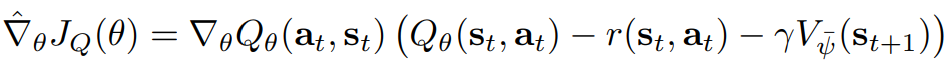
폴리시 파라미터는 KL-L-divergence를 최소하하여 업데이트 한다.
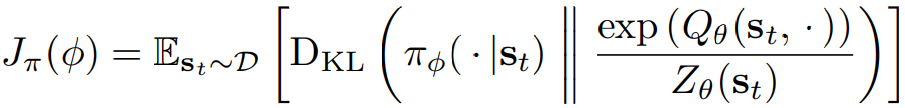
J_pi를 최소화하는 것에는 여러 옵션이 작용한다. 고전적으로는 likelihood ratio gradient estimator를 사용한다. likelihood ratio gradient estimator는 정책과 타겟 desity network 그라디언트에 역전파가 필요하지 않다. 그러나 target density는 미분가능한 뉴럴네트워크를 사용하는 Q 펑션을 사용하므로 reparameterization trick을 사용하는 것이 편리하다. 따라서 뉴럴 내네트워크 트랜스폼을 reparameterization한다.
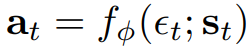
입실론은 input noise vector이다. objective 를 다시 표기하면 아래와 같다.
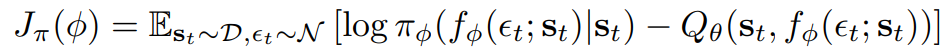


두 개의 Q 펑션을 사용하여 기치 기반 메소드의 성능을 저하시키는 positive bias를 완하시킨다. 특히 두개의 Q 펑션을 세타를 이용하여 표기하고 J_Q를 최적화한다.
5. Experiments
실험의 목적은 샘플 복잡성과 안전성을 이전의 off-policy와 on-policy deep RL의 성능과 비교하는 것이다. 어려운 OpenAI gym 환경과 humanoid task에서부터 간단한 태스크까지 여러 환경에서 실험을 진행했다. baseline으로는 DDPG,PPO와 SQL을 사용한다. SQL도 두개의 Q 펑션을 가지고 있고 이 점은 대부분의 환경에서 성능을 향상 시킨다. 추가로 TD3와 Trust-PCL을 사용한다.
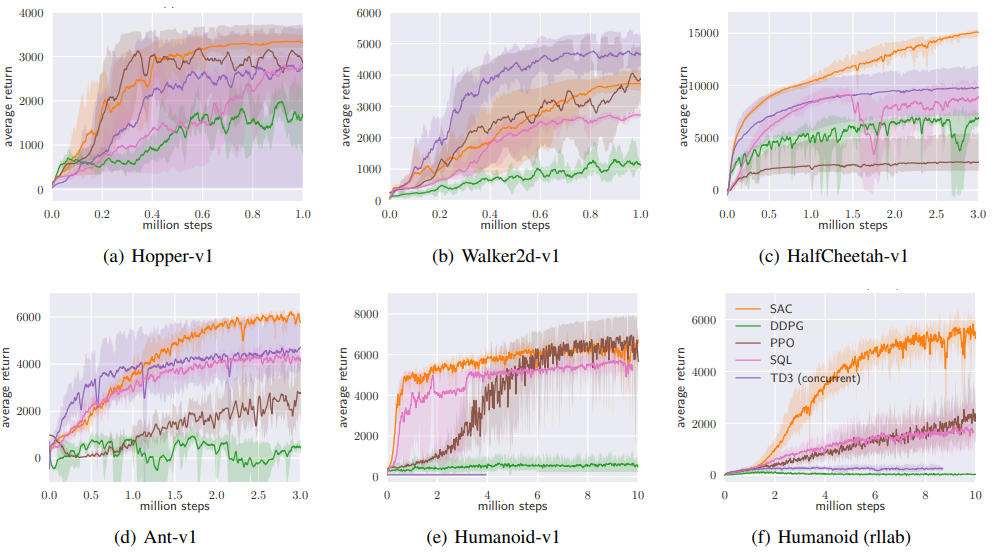
5.1. Comparative Evaluation
전반적으로 SAC의 성능이 좋은 것을 위의 그래프를 통해서 알수있다. DDPG는 ant와 Humanoid(e와 f)모두 좋은 성적을 보이지 못했다. SAC는 PPO보다 빠르게 학습했는데 이것은 PPO가 복잡한 태스크에서 batch size가 크기 때문에 나타난 결과이다. SQL은 모든 태스크를 성공했지만 SAC보다 학습 속도도 느리고 성능도 조금씩 떨어진다.
5.2. Ablation Study
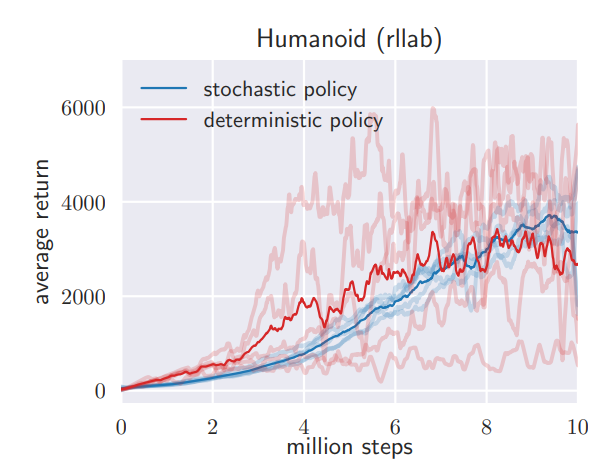
Stochastic vs. deterministic policy :SAC는 maximum entropy objective를 사용하여 stochastic policy들을 학습한다.
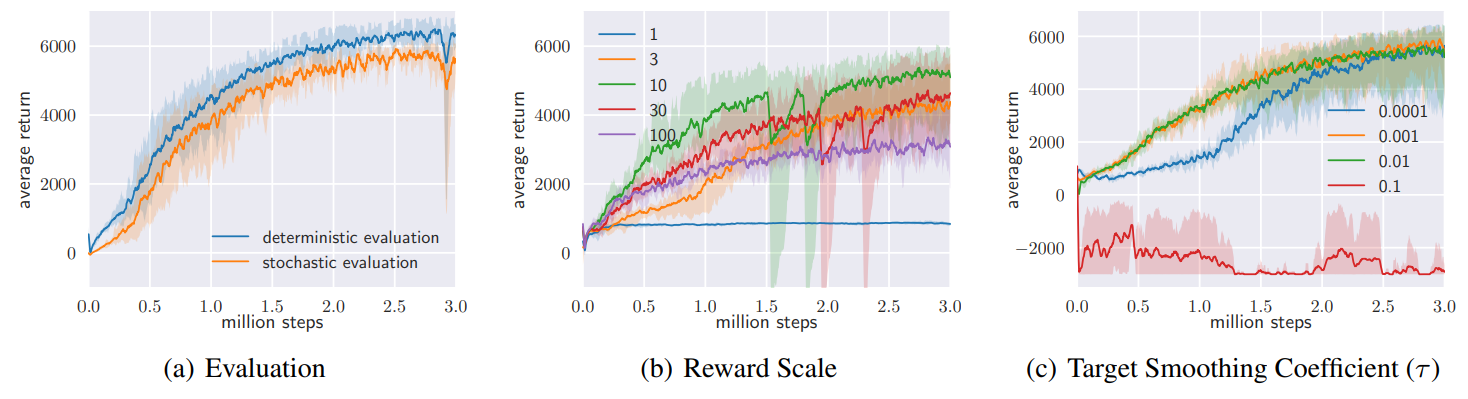
Policy evaluation. SAC는 stochastic policy로 수렴하기 때문에 최상의 성능을 만드는 최종 정책 선정에 도움을 준다. 평가를 위해 위해 정책 분포의 평균을 근사하였다. 위 그래프에서 (a)를 보면 deterministic이 stochastic보다 좋은 성능을 보여준다.
Reward scale. SAC는 확률성을 제어하기 때문에 reward signal의 scaling에 민감하다. 그래프 (b)는 reward scale이 바뀌면 어떻게 성능에 변화가 생기는지를 보여준다. 작은 reward magnitude에서는 정책이 uniform해지고 점차 reward signal 사용이 어려워진다. 큰 reward magnitude는 처음에는 학습이 빨리 되는 것으로 보이나 결과적으로 deterministic으로 변하고 좋지 않은 local minima로 이끌게 되어 적절한 탐색을 불가능하게 한다.
Target network update. 안정성을 위해서 target network를 별도로 사용하는 것이 일반적이다. 스무딩 상수인 τ를 이용하여 target network의 weight를 업데이트한다. 그래프 (c)는 τ에 따라 달라지는 성능을 보여준다. 너무 큰 값에서는 불안정성이 발생하고 너무 작으며 학습 속도가 느려진다. 0.005로 고정한 후 모든 태스크들을 비교했더니 (exponentially moving average) 모든 태스크에서 좋은 성능을 얻었다.
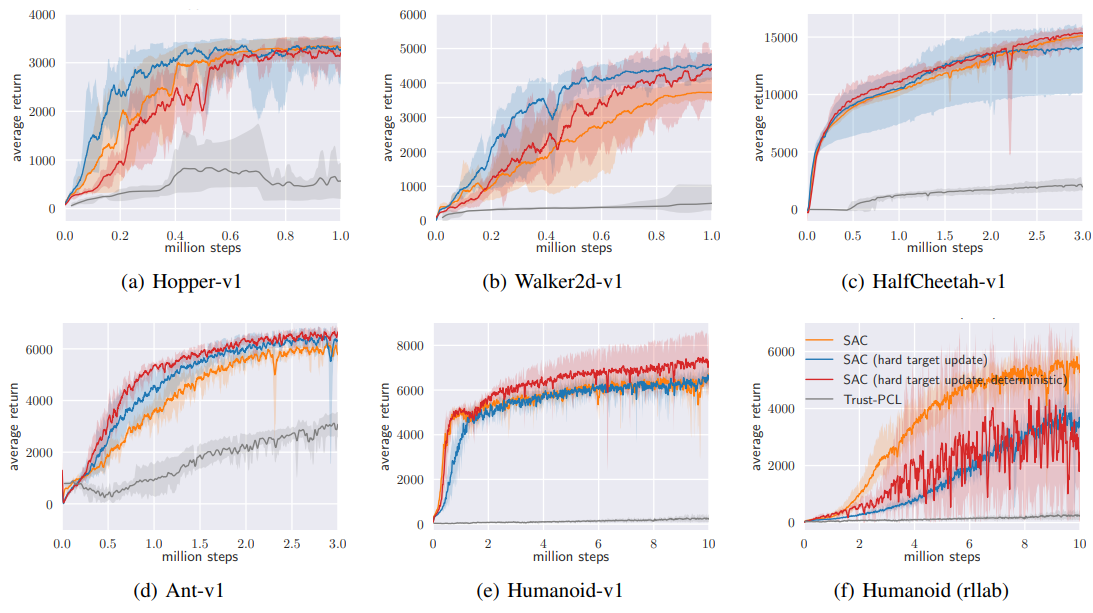
6. Conclusion ❤❤
SAC가 복잡한 환경에서 샘플링에 있어서 효율적이고 안정성이 높다는 것을 확인하였다. 최적의 policy에 도달하는 Soft policy iteration를 사용하였다. SAC는 복잡한 도메인에서 state-of-the-art RL 메소드들을 능가하는 성능을 보여줬다.
부족한게 너무 많지만 한번 쑥 훑었다는 것에 목표를 두고SAC 논문 리뷰를 작성해보았다.
이제 정말 끝!!!!
'공부쓰 > Paper reviewth' 카테고리의 다른 글
| [CoRL 2020] Learning Latent Representations to Influence Multi-Agent Interaction (2) | 2021.02.05 |
|---|---|
| [CoRL 2020] Accelerating Reinforcement Learning with Learned Skill Priors (1) | 2021.01.08 |
| 논문 읽는 나만의 꿀팁s... (6) | 2020.12.20 |



